做网站SEO优化的人应该要对搜索引擎的基本原理有一些了解,如搜索引擎发现网址到该页面拥有排名,以及后续更新的整个过程中,搜索引擎到底是怎么工作的。对于专业的算法不必进行深入的研究,但是对于搜索引擎工作中的策略和算法原理要有个简单的认知,这样才能更有效地开展网站SEO优化工作,知其然也要知其所以然。当然,也有一些朋友不懂这些,照样做得有声有色,但是对于搜索引擎工作原理,懂总比不懂要好一些。
其实当你了解了搜索引擎的工作流程、策略和基本算法后,就可以在一定程度上避免因为不当操作而带来的处罚,同时也可以快速分析出很多搜索引擎搜索结果异常的原因。有搜索行为的地方就有搜索引擎,站内搜索、全网搜索、垂直搜索等都会用到搜索引擎。接下来,智美科技会根据从业认知,讨论一下搜索引擎的基本架构。百度、Google等综合搜索巨头肯定有着更为复杂的架构和检索技术,但宏观上的基本原理都差不多。
搜索引擎的大概架构如图所示。可以分成虚线左右两个部分:一部分是主动抓取网页进行一系列处理后建立索引,等待用户搜索;另一部分是分析用户搜索意图,展现用户所需要的搜索结果。

索引擎主动抓取网页,并进行内容处理、索引部分的流程和机制一般如下。
步骤 01 派出Spider,按照一定策略把网页抓回到搜索引擎服务器;
步骤 02 对抓回的网页进行链接抽离、内容处理,消除噪声、提取该页主题文本内容等;
步骤 03 对网页的文本内容进行中文分词、去除停止词等;
步骤 04 对网页内容进行分词后判断该页面内容与已索引网页是否有重复,剔除重复页,对剩余网页进行倒排索引,然后等待用户的检索。
当有用户进行查询后,搜索引擎工作的流程机制一般如下。
步骤 01 先对用户所查询的关键词进行分词处理,并根据用户的地理位置和历史检索特征进行用户需求分析,以便使用地域性搜索结果和个性化搜索结果展示用户最需要的内容;
步骤 02 查找缓存中是否有该关键词的查询结果,如果有,为了最快地呈现查询结果,搜索引擎会根据当下用户的各种信息判断其真正需求,对缓存中的结果进行微调或直接呈现给用户;
步骤 03 如果用户所查询的关键词在缓存中不存在,那么就在索引库中的网页进行调取排名呈现,并将该关键词和对应的搜索结果加入到缓存中;
步骤 04 网页排名是根据用户的搜索词和搜索需求,对索引库中的网页进行相关性、重要性(链接权重分析)和用户体验的高低进行分析所得出的。用户在搜索结果中的点击和重复搜索行为,也可以告诉搜索引擎,用户对搜索结果页的使用体验。这块儿是近来作弊最多的部分,所以这部分会伴随着搜索引擎的反作弊算法干预,有时甚至可能会进行人工干预。
按照上述搜索引擎的架构,在整个搜索引擎工作流程中大概会涉及Spider、内容处理、分词、去重、索引、内容相关性、链接分析、判断页面用户体验、反作弊、人工干预、缓存机制、用户需求分析等模块。以下会针对各模块进行详细讨论,也会顺带着对现在行业内讨论比较多的相关问题进行原理分析。
Spider也就是大家常说的爬虫、蜘蛛或机器人,是处于整个搜索引擎最上游的一个模块,只有Spider抓回的页面或URL才会被索引和参与排名。需要注意的是,只要是Spider抓到的URL,都可能会参与排名,但参与排名的网页并不一定就被Spider抓取到了内容,比如有些网站屏蔽搜索引擎Spider后,虽然Spider不能抓取网页内容,但是也会有一些域名级别的URL在搜索引擎中参与了排名(例如天猫上的很多独立域名的店铺)。根据搜索引擎的类型不同,Spider也会有不同的分类。大型搜索引擎的Spider一般都会有以下需要解决的问题,也是和SEO密切相关的问题。
首先,Spider想要抓取网页,要发现网页抓取入口,没有抓取入口也就没有办法继续工作,所以首先要给Spider一些网页入口,然后Spider顺着这些入口进行爬行抓取,这里就涉及抓取策略的问题。抓取策略的选择会直接影响Spider所需要的资源、Spider所抓取网页占全网网页的比例,以及Spider的工作效率。那么Spider一般会采用什么样的策略抓取网页呢?
其次,网页内容也是有时效性的,所以Spider对不同网页的抓取频率也要有一定的策略性,否则可能会使得索引库中的内容都很陈旧,或者该更新的没更新,不该更新的却浪费资源更新了,甚至还会出现网页已经被删除了,但是该页面还存在于搜索结果中的情况。那么Spider一般会使用什么样的再次抓取和更新策略呢?
再次,互联网中的网页总有一部分是没有外部链接导入的,也就是常说的“暗网”,并且这部分网页也是需要呈现给广大网民浏览的,此时Spider就要想方设法针对处于暗网中的网页进行抓取。当下百度是如何来解决这个暗网问题的呢?
最后,大型搜索引擎的Spider不可能只有一个,为了节省资源,要保证多个Spider同时作业且抓取页面不重复;又由于各地区数据中心分配问题,搜索引擎一般不会把Spider服务器放置在一个地区,会多地区同时作业,这两方面就涉及分布式抓取的策略问题。那么一般搜索引擎的Spider会采用什么样的分布抓取策略呢?
接下来逐一介绍一般的搜索引擎Spider在面临以上问题时采用的是什么策略,并详细地了解一下整个搜索引擎最上游的Spider到底是如何工作的,以及一个优秀的Spider程序应该有哪些特点。
按照现在网络上所有Spider的作用及表现出来的特征,可以将其分为3类:批量型Spider、增量型Spider和垂直型Spider。
1.批量型Spider
一般具有明显的抓取范围和目标,设置抓取时间的限制、抓取数据量的限制或抓取固定范围内页面的限制等,当Spider的作业达到预先设置的目标就会停止。普通站长和SEO人员使用的采集工具或程序,所派出的Spider大都属于批量型Spider,一般只抓取固定网站的固定内容,或者设置对某一资源的固定目标数据量,当抓取的数据或者时间达到设置限制后就会自动停止,这种Spider就是很典型的批量型Spider。
2.增量型Spider
增量型Spider也可以称之为通用爬虫。一般可以称为搜索引擎的网站或程序,使用的都是增量型Spider,但是站内搜索引擎除外,自有站内搜索引擎一般是不需要Spider的。增量型Spider和批量型Spider不同,没有固定目标、范围和时间限制,一般会无休止地抓取下去,直到把全网的数据抓完为止。增量型Spider不仅仅抓取尽可能全的页面,还要对已经抓取到的页面进行相应的再次抓取和更新。因为整个互联网是在不断变化的,单个网页上的内容可能会随着时间的变化不断更新,甚至在一定时间之后该页面会被删除,优秀的增量型Spider需要及时发现这种变化,并反映给搜索引擎后续的处理系统,对该网页进行重新处理。当前百度、Google网页搜索等全文搜索引擎的Spider,一般都是增量型Spider。
3.垂直型Spider
垂直型Spider也可以称之为聚焦爬虫,只对特定主题、特定内容或特定行业的网页进行抓取一般都会聚焦在某一个限制范围内进行增量型的抓取。此类型的Spider不像增量型Spider一样追求大而广的覆盖面,而是在增量型Spider上增加一个抓取网页的限制,根据需求抓取含有目标内容的网页,不符合要求的网页会直接被放弃抓取。对于网页级别纯文本内容方面的识别,现在的搜索引擎Spider还不能百分之百地进行准确分类,并且垂直型Spider也不能像增量型Spider那样进行全互联网爬取,因为那样太浪费资源。所以现在的垂直搜索引擎如果有附属的增量型Spider,那么就会利用增量型Spider以站点为单位进行内容分类,然后再派出垂直型Spider抓取符合自己内容要求的站点;没有增量型Spider作为基础的垂直搜索引擎,一般会采用人工添加抓取站点的方式来引导垂直型Spider作业。当然在同一个站点内也会存在不同的内容,此时垂直型Spider也需要进行内容判断,但是工作量相对来说已经缩减优化了很多。现在一淘网、优酷下的搜库、百度和Google等大型搜索引擎下的垂直搜索使用的都是垂直型Spider。虽然现在使用比较广泛的垂直型Spider对网页的识别度已经很高,但是总会有些不足,这也使得垂直类搜索引擎上的SEO有了很大进步空间。
本书主要讨论网页搜索的SEO,所以讨论的内容以增量型Spider为主,也会简单涉及垂直型Spider方面的内容,其实垂直型Spider完全可以看作是做了抓取限制的增量型Spider。
2.1.2 Spider的抓取策略
在大型搜索引擎Spider的抓取过程中会有很多策略,有时也可能是多种策略综合使用。这里简单介绍一下比较简单的Spider抓取策略,以辅助大家对Spider工作流程的理解。Spider抓取网页,在争取抓取尽可能多网页的前提下,首先要注意的就是避免重复抓取,为此Spider程序一般会建立已抓取URL列表和待抓取URL列表(实际中是由哈希表来记录URL的两个状态)。在抓取到一个新页面时,提取该页面上的链接,并把提取到的链接和已抓取URL列表中的链接进行逐一对比,如果发现该链接已经抓取过,就会直接丢弃,如果发现该链接还未抓取,就会把该链接放到待抓取URL队列的末尾等待抓取。

(1)已经抓取过的页面,即Spider已经抓取过的页面。
(2)待抓取页面,也就是这些页面的URL已经被Spider加入到了待抓取URL队列中,只是还没有进行抓取。
(3)可抓取页面,Spider根据互联网上的链接关系最终是可以找到这些页面的,也就是说当下可能还不知道这些页面的存在,但是随着增量型Spider的抓取,最终会发现这些页面的存在。
(4)暗网中的页面,这些网页和表层网络上的网页是脱钩的,可能这些页面中有链接指向以上三类网页,但是通过以上三类网页并不能找到这些页面。比如,网站内需要手动提交查询才能获得的网页,就属于暗网中的网页。据估计暗网网页要比非暗网网页大几个数量级。
全文搜索引擎的Spider一直致力于抓取全网的数据,现在Spider对于非暗网网页已经具备大量高效的抓取策略。对于暗网的抓取,各个搜索引擎都在努力研究自己不同的暗网Spider抓取策略,百度为此推出了“阿拉丁”计划,鼓励有优质资源的网站把站内资源直接以XML文件的形式提交给百度,百度会直接进行抓取和优先排名显示。这里主要讨论Spider针对非暗网中网页的抓取策略。
当Spider从一个入口网页开始抓取时,会获得这个页面上所有的导出链接,当Spider随机抓取其中的一个链接时,同样又会收集到很多新的链接。此时Spider面临一个抓取方式的选择:
(1)先沿着一条链接一层一层地抓取下去,直到这个链接抓到尽头,再返回来按照同样的规则抓取其他链接,也就是深度优先抓取策略。
(2)还是先把入口页面中的链接抓取一遍,把新发现的URL依次进行入库排列,然后对这些新发现的页面进行遍历抓取,再把最新发现的URL进行入库排列等待抓取,依次抓取下去,也就是广度优先抓取策略。
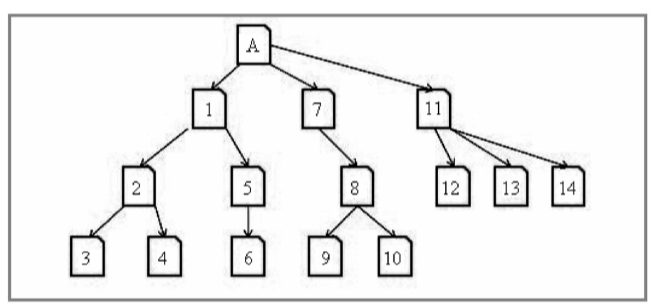
①深度优先策略
深度优先策略即一条道走到黑,当沿着一个路径走到无路可走时,再返回来走另一条路。如图所示为深度优先抓取策略的示意图,假设A页面为Spider的入口,Spider在A页面上发现了1、7、11三个页面的链接,然后Spider会按照图中数字所标示的顺序依次进行抓取。当第一条路径抓到3页面时到头了,就会返回2页面抓取第二条路径中的4页面,在4页面也抓到头了,就会返回1页面抓取第三条路径中的5页面,并顺着一路抓下去,抓到头后会按照之前的规则沿一条一条路径抓下去。
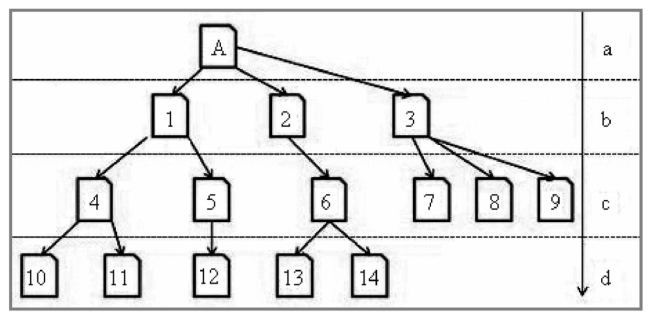
②广度优先策略
广度优先策略即Spider在一个页面上发现多个链接时,并不是一条道走到黑,顺着一个链接继续抓下去,而是先把这些页面抓一遍,然后再抓从这些页面中提取下来的链接。如图所示为广度优先抓取策略的示意图,假设A页面为Spider的入口,Spider在A页面上发现了1、2、3三个页面。当抓完1网页时,只是把1网页中4和5网页的链接放入待抓取URL列表,并不会继续抓1页面中的其他链接,而是抓2页面。当b级页面抓取完成时,才会抓取从b级页面中提取到c级页面中的4、5、6、7、8、9六个页面,等c级页面抓取完成后,再抓取从c级页面中提取到的d级新页面,依次持续抓取下去。
理论上Spider不论采用深度优先策略还是广度优先策略,只要时间足够,都可以把整个互联网上的网页抓取一遍。但是搜索引擎本身的资源也是有限的,快速抓取全互联网有价值的页面只是一种奢望而已,所以搜索引擎的Spider不是只使用一种策略无限地抓取新页面,而是采用两种策略相结合的方式来进行抓取。一般Spider可以在域名级别的页面使用广度优先抓取策略,尽可能地收集更多的网站。在网站内页级别一般会根据网站的权重综合使用广度和深度优先抓取策略,也就是说网站的权重越高,抓取量也会越大,刚上线的网站可能只会被抓一个首页。这也是很多新网站在一定时间内,在搜索引擎中只首页被索引的原因之一。
上面讨论的两个策略是站在Spider只是单纯想抓取全互联网数据的基础上,所需要选择的策略。实际在搜索引擎中,虽然Spider在尽力保证抓取页面的全面性,但是由于自身资源有限,所以在尽力抓取全网的同时,还要考虑对重要页面的优先抓取。这个“重要页面”的定义应该是指在互联网中比较重要的页面,该页面内容应该具有影响力比较大、需要了解该内容的网民比较多或时效传播性比较强的特点。体现到抓取策略上,就是这个页面的导入链接很多,或者是权重高的大站中的网页。总结来说,就是两个策略:重要网页优先抓取策略和大站链接优先抓取策略。
(1)重要页面优先抓取策略
一般认为页面的重要性,除了受寄主站点本身的质量和权重影响以外,就看导入链接的多少和导入链接的质量了。Spider抓取层面上的“重要页面”一般由导入的链接来决定。在前面所讨论的抓取策略中,Spider一般都会把新发现的未抓取过的URL依次放到待抓取URL队列的尾端,等待Spider按顺序抓取。在重要页面优先抓取的策略中就不是这样的了,这个待抓取URL队列的顺序是在不断变化的。排序的依据是:页面获得的已抓取页面链接的多少和链接权重的高低。如图2-2所示,按照普通的抓取策略,Spider的抓取顺序应该是1、2、3、4、5、6、7……,使用重要页面优先策略后,待抓取页面的排序将变成6、4、5……。
(2)大站优先策略
大站优先策略,这个思路很简单。被搜索引擎认定为“大站”的网站,一定有着稳定的服务器、良好的网站结构、优秀的用户体验、及时的资讯内容、权威的相关资料、丰富的内容类型和庞大的网页数量等特征,当然也会相应地拥有大量高质量的外链。也就是在一定程度上可以认定这些网站的内容就可以满足相当比例网民的搜索请求,搜索引擎为了在有限的资源内尽最大的努力满足大部分普通用户的搜索需求,一般就会对大站进行“特殊照顾”。因此大家可以看到新浪、网易类网站上自主发布的内容几乎都会被百度秒收,因为百度搜索的Spider在这些网站上是7×24小时不间断抓取的。如果有新站的链接出现在这些网站的重要页面上,也会相应地被快速抓取和收录。曾经有朋友试验新站秒收的策略:把新站的链接推到一些大站的首页,或挂到大站首页所推荐的页面中,效果非常不错。
这两个策略与前面所讨论的广度优先策略和深度优先策略相结合的抓取方式是有共同点的。比如,从另一个角度来看,如果Spider按照前两个策略抓取,一个页面获得的导入链接越多,被提前抓到的几率就越大,也就是和重要页面优先抓取是趋同的;在Spider资源有限的情况下广度优先策略和深度优先策略的结合分配本身就会以站点的大小进行区别对待,大网站的页面有着先天的高重要程度,往往也容易获得更多的链接支持。所以宏观来看,这几个策略在抓取表现上有相近之处,在实际的抓取过程中相辅相成。
相对于整个互联网的网页来说,Spider的资源再充足也是有限的,所以优秀的Spider程序应该首先保证对重要网页的抓取,然后才是尽力抓取尽可能全的互联网网页信息。由此也可以看出依靠外部链接来引导Spider和提升网站权重,以及依靠内容长期运营网站权重的重要性。




